Reinforcement Learning Course 2 - Week 4
TLDR
- Temporal Difference Learning for Control.
- SARSA, Q-learning and Expected SARSA.
- How Q-learning is actually a special case of Expected SARSA.
SARSA: What is it?
Remember the Temporal difference method policy update equation?
\[\begin{equation} V(s_t) \leftarrow V(s_t) + \alpha [R_{t+1} + \gamma V(s_{t+1}) - V(s_t)] \end{equation}\]This equation updates the state-value function only. The value of a state is determined by the immediate reward received and the estimated value of the next state. But the reward also depends on the action taken. We are missing this part. If you are right at the front of the goal post without any defenders and the goalkeepr, if you do not shoot - in other words take action, you will not get any reward! So the action is also important. Sometimes the action is more important than the state itself (for example, in the above case).
Now what if we want to update the action-value function instead of the state-value function? We can do that by updating the state-value function into an action value function, that is by replacing $V(s)$ with $Q(s,a)$. The $Q$ is the value of a certain action $a$ taken at a certain state $s$. The update equation becomes:
\[\begin{equation} Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha [R_{t} + \gamma Q(s_{t+1}, a_{t+1}) - Q(s_t, a_t)] \end{equation}\]This is the SARSA algorithm. The name SARSA comes from the fact that we are using the set of State, Action, Reward, State, Action to update the action-value function.
This SARSA algorithm is the Generalized Policy Improvement for TD algorithm. Just like we had discussed in Course 1 Week 4 blog.
But here is an issue! What if the action taken at the next step $s_{t+1}$ does not give us the best value $Q(s_{t+1})$? Or in other words the policy is not the most optimum? For example, your policy is to give long passes always. But in the front of the goal post, will you follow your policy and shoot for long pass to another team mate? Or will you go for the goal? You should choose the action with the maximum reward right?
Q learning!
Intuition
Suppose in the game of the football, you have multiple choices to make. You can either go for long pass, or go for short pass or go for shoot to the Goal post! Which action to take? What about , each time you take the action based on the maximum value? How can we know the value? (That is the point of Q learning!) For now, lets assume we know what is the value of state action pair in the game.
If you are at the front of a D-box, what will you do? Shoot or Pass?
Lets assume you have the following option
$Q(s_t=Dbox, a=shoot) = 0.1 $ $Q(s_t=Dbox, a=pass) = 0.5 $
and the player who is in front of the Goal post
$Q(s_t=goal_post, a=shoot) = 0.9$ $Q(s_t=goal_post, a=pass) = 0.6$
The best set of actions (or policy) is to take the action with the maximum value at each state. So at D-box you will “pass”, and expect the player in front of the goalpost to “shoot”. How can you know that the player will “shoot” when you “pass” ? You cannot be sure about it! But you can “expect” him to “shoot” based on your experience. So you should train yourself to “pass” in that position “expecting” the player will “shoot”. Not that he will “pass” again! This is the intuition behind Q learning.
Q learning update equation
The Q learning update equation is as follows:
\[Q(s, a) \leftarrow Q(s, a) + \alpha [R + \gamma \underbrace{\max_{a'} Q(s', a')}_{\text{Best possible action}} - Q(s, a)]\]That is we are updating the action-value function of the current state-action pair expecting that the next action taken will be the one with the maximum value. This differs from SARSA where we take the next action based on the current policy.
\[Q(s, a) \leftarrow Q(s, a) + \alpha [R + \gamma \underbrace{Q(s', a')}_{\text{Actual next action}} - Q(s, a)]\]
How is Q-learning off-policy?
If we can recall the off-policy learning and the on-policy learning from the previous blogs, the on-policy learning updateds the value of the action taken based on the current policy. On the other hand, off-policy learning updates the value of the action taken based on a different policy. In Q-learning, the action taken is based on the behaviour policy. But the update is based on the maximum value action which is different from the behaviour policy. Hence Q-learning is off-policy.
Why does not Q-learning need importance sampling?
Remember Importance sampling from Course 2 Week 2 blog?
In the monte-carlo off-policy learning we needed importance sampling because the action was taken based on the behaviour policy while the update was done to the target policy. Hence, we had to adjust the expected reward based on the statistical trick of importance sampling. However, in this case we are updating the value based on the maximum valu action which is independant of the behaviour policy. So we do not need to adjust the expected reward based on the behaviour policy. That is why Q-learning does not need importance sampling.
Expected SARSA
Recall the SARSA algorithm? The equation is
\[\begin{equation} Q(s, a) \leftarrow Q(s, a) + \alpha [R + \gamma Q(s', a') - Q(s, a)] \end{equation}\]As we know the policy already, why not we calculate the expected value using the policy for the next step? Which is to average the rewards for each action based on the probability of that action. The equation is
\[Q(s, a) \leftarrow Q(s, a) + \alpha [R + \gamma \underbrace{\sum_{a'} \pi(a'|s')Q(s', a')}_{\text{Expected next action}} - Q(s, a)]\]Difference between SARSA and Expected SARSA
The difference between SARSA and Expected SARSA is that the update equation in the SARSA is not considering the probability distribution of the policy. While the Expected SARSA is considering the probability distribution of the policy. This makes the updated action values in Expected SARSA more accurate.
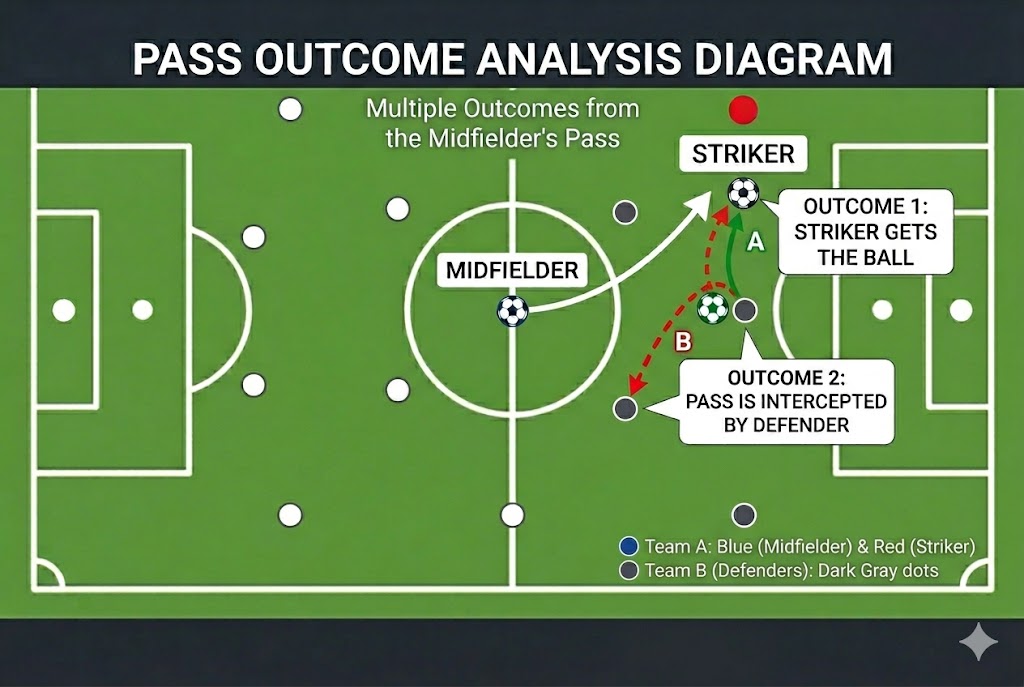
Let’s think about an intuition from Soccer.
 The above image is generated using Gemini.
The above image is generated using Gemini.
Suppose you are the midfielder whose job is to pass the ball to the striker. But in real life you are not entirely in control of your pass; are you? Think about it! You will pass to the striker (in other words, take the $a_{pass}$) to the forward. But there are possibilities that may happen! The striker may get the ball ,OR the defender from the other side may intercept your ball as well?!!! In the case of Q-learning we are updating the value of the current state anticipating the only one deterministic outcome of the current action and the best plausible action from the next state. But there are chances or (probabilities) of other outcomes from the same action, and hence other plausible next states (or $s’\epsilon S’$). Then the most accurate value of the current state-action pair should come out of all plausible outcomes from the current action and next states. This is the intuition behind Expected SARSA.
Generality of Expected SARSA
Let’s look at the update equation of Expected SARSA again:
\[Q(s, a) \leftarrow Q(s, a) + \alpha [R + \gamma \underbrace{\sum_{a'} \pi(a'|s')Q(s', a')}_{\text{Expected next action}} - Q(s, a)]\]The target policy is different from the behaviour policy. The target policy is the one we are using to calculate the expected value of the next action, while the behaviour policy is the one we are using to take the action. Hence, Expected SARSA is an off-policy learning algorithm.
What if we have a greedy policy? In that case, the probability of the action with the maximum value taken will be 1 and the probability of all other actions will be 0. Hence, the update equation will become: \(Q(s, a) \leftarrow Q(s, a) + \alpha [R + \gamma \underbrace{Q_{\max}(s', a')}_{\text{Best possible action}} - Q(s, a)]\)
This is the exact same update equation for Q-learning! Hence, we can say that the Q-learning is a special case of Expected SARSA where the policy is greedy!
Conclusion
Thats all! I tried to cover the intuition behind SARSA, Q-learning and Expected SARSA. I hope you will find it useful.
References
- All the images in this blog are generated using Gemini.
- The contents of this blog are based on the lectures in Coursera Reinforcement Learning Specialization by University of Alberta. The lectures are available at Coursera.